Normalization
Last updated: 2022-02-28
Checks: 7 0
Knit directory: STUtility_web_site/
This reproducible R Markdown analysis was created with workflowr (version 1.7.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20191031) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 64ae8be. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: analysis/.DS_Store
Ignored: analysis/manual_annotation.png
Ignored: pre_data/
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/Normalization.Rmd) and HTML (docs/Normalization.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| html | d41bcb0 | Ludvig Larsson | 2022-02-28 | Build site. |
| html | 0dafcee | Ludvig Larsson | 2021-05-06 | Build site. |
| html | df62517 | Ludvig Larsson | 2021-05-06 | Build site. |
| html | 88b046f | Ludvig Larsson | 2021-05-05 | Build site. |
| html | 2523b70 | Ludvig Larsson | 2021-05-05 | Changed names of docs |
| Rmd | 363f911 | Ludvig Larsson | 2021-05-05 | Changed names of Rmds |
SCTransform (Seurat)
In order to normalize the data we recommend using variance stabilized transformation available in the SCTransform function in Seurat as of v3.0.
Following the rationale expressed below, we transform the data according to the Seurat workflow.
se <- SCTransform(se)Regressing out batch effects
When deciding on a normalization strategy using SCTransform it is important to consider potential batch effects that could confound downstream analysis. Such batch effects could for example arise between different sample specimens, storage times, array slides etc. and even between consecutive sections prepared on the same slide. The experimental setup is crucial to make it possible to combat such batch effects and it is important to carefully think through if and how they should be removed to make the biological variation in your data more meaningful. Some of these effects can be effectively removed during normalization with SCTransform by specifying your batches with the vars.to.regress option.
For example if you want to regress out the “section number” from the data you need to make sure that you have a variable in your meta.data giving a unique ID for each section. If you don’t have this information in your meta.data you can get it from the “Staffli” object stored inside the Seurat object. Then you can simply set vars.to.regress = "section" when running SCTransform to correct for potential technical effects separating the two sections.
# Add a section column to your meta.data
se$section <- paste0("section_", GetStaffli(se)[[, "sample", drop = T]])
# Run normalization with "vars.to.regress" option
se.batch.cor <- SCTransform(se, vars.to.regress = "section")Note: for comprehensive tutorials in the different options and workflow possibilities available within Seurat, we recommend looking at their website https://satijalab.org/seurat/.
Rationale of approach
Each spot in a Spatial Transcriptomics dataset typically contains RNA from a mixture of cells so why would we apply a workflow that was developed for single-cell RNAseq data? We can calculate some properties to visually inspect the data to see that ST data have similar properties to that of scRNAseq data.
library(Matrix)
library(magrittr)
library(dplyr)
library(ggplot2)
# Get raw count data
umi_data <- GetAssayData(object = se, slot = "counts", assay = "RNA")
dim(umi_data)
# Calculate gene attributes
gene_attr <- data.frame(mean = rowMeans(umi_data),
detection_rate = rowMeans(umi_data > 0),
var = apply(umi_data, 1, var),
row.names = rownames(umi_data)) %>%
mutate(log_mean = log10(mean), log_var = log10(var))
# Obtain spot attributes from Seurat meta.data slot
spot_attr <- se[[c("nFeature_RNA", "nCount_RNA")]]
p1 <- ggplot(gene_attr, aes(log_mean, log_var)) +
geom_point(alpha = 0.3, shape = 16) +
geom_density_2d(size = 0.3) +
geom_abline(intercept = 0, slope = 1, color = 'red') +
ggtitle("Mean-variance relationship")
# add the expected detection rate under Poisson model
x = seq(from = -2, to = 2, length.out = 1000)
poisson_model <- data.frame(log_mean = x, detection_rate = 1 - dpois(0, lambda = 10^x))
p2 <- ggplot(gene_attr, aes(log_mean, detection_rate)) +
geom_point(alpha = 0.3, shape = 16) +
geom_line(data = poisson_model, color='red') +
ggtitle("Mean-detection-rate relationship")
p1 - p2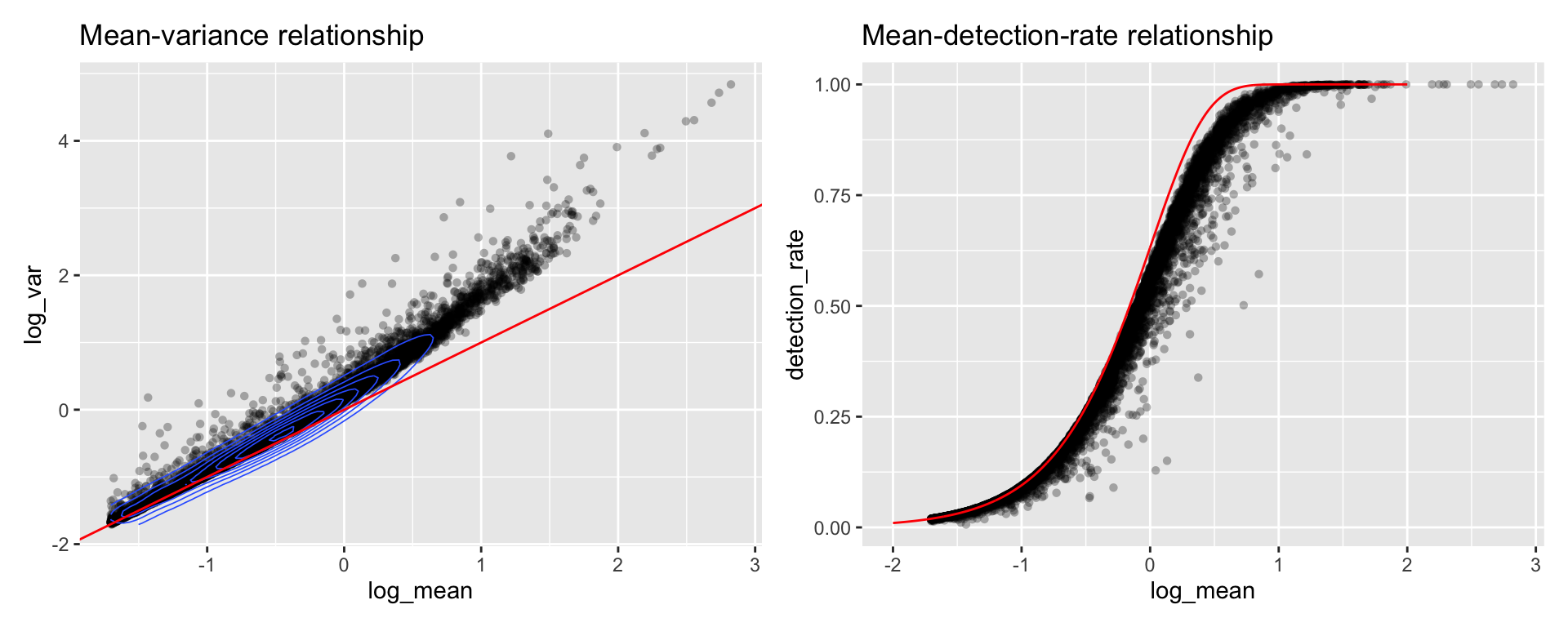
We can see from the mean-variance and Mean-detection-rate scatter plots that genes show overdispersion compared to what would be expected under a Poisson model. Because these properties are shared between ST and scRNAseq data we have reasoned that the workflow presented in the Seurat package should be applicable for ST data as well. It is important however to keep in mind that each spots contains a mixture of cell types and should be interpreted as a morphological unit in the context of a tissue section.
A work by Joseph Bergenstråhle and Ludvig Larsson
sessionInfo()R version 4.0.3 (2020-10-10)
Platform: x86_64-apple-darwin13.4.0 (64-bit)
Running under: macOS Mojave 10.14.6
Matrix products: default
BLAS/LAPACK: /Users/ludviglarsson/anaconda3/envs/R4.0/lib/libopenblasp-r0.3.12.dylib
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] dplyr_1.0.8 magrittr_2.0.1 Matrix_1.3-2 STutility_0.1.0
[5] ggplot2_3.3.5 SeuratObject_4.0.0 Seurat_4.0.2 workflowr_1.7.0
loaded via a namespace (and not attached):
[1] utf8_1.2.1 reticulate_1.18 tidyselect_1.1.1
[4] htmlwidgets_1.5.3 grid_4.0.3 Rtsne_0.15
[7] munsell_0.5.0 codetools_0.2-18 ica_1.0-2
[10] units_0.7-1 future_1.21.0 miniUI_0.1.1.1
[13] withr_2.4.1 colorspace_2.0-0 highr_0.8
[16] knitr_1.31 uuid_0.1-4 rstudioapi_0.13
[19] ROCR_1.0-11 tensor_1.5 listenv_0.8.0
[22] labeling_0.4.2 git2r_0.28.0 polyclip_1.10-0
[25] farver_2.1.0 rprojroot_2.0.2 coda_0.19-4
[28] parallelly_1.25.0 LearnBayes_2.15.1 vctrs_0.3.8
[31] generics_0.1.0 xfun_0.20 R6_2.5.0
[34] doParallel_1.0.16 isoband_0.2.4 Morpho_2.8
[37] ggiraph_0.7.8 manipulateWidget_0.11.0 spatstat.utils_2.2-0
[40] assertthat_0.2.1 promises_1.2.0.1 scales_1.1.1
[43] imager_0.42.8 gtable_0.3.0 globals_0.14.0
[46] bmp_0.3 processx_3.5.1 goftest_1.2-2
[49] rlang_1.0.1 zeallot_0.1.0 akima_0.6-2.1
[52] systemfonts_1.0.1 splines_4.0.3 lazyeval_0.2.2
[55] spatstat.geom_2.3-0 rgl_0.105.22 yaml_2.2.1
[58] reshape2_1.4.4 abind_1.4-5 crosstalk_1.1.1
[61] httpuv_1.5.5 tools_4.0.3 spData_0.3.8
[64] ellipsis_0.3.2 spatstat.core_2.3-0 raster_3.4-10
[67] jquerylib_0.1.3 RColorBrewer_1.1-2 proxy_0.4-25
[70] Rvcg_0.19.2 ggridges_0.5.3 Rcpp_1.0.6
[73] plyr_1.8.6 classInt_0.4-3 purrr_0.3.4
[76] ps_1.6.0 rpart_4.1-15 dbscan_1.1-6
[79] deldir_1.0-6 pbapply_1.4-3 viridis_0.6.1
[82] cowplot_1.1.1 zoo_1.8-9 ggrepel_0.9.1
[85] cluster_2.1.1 colorRamps_2.3 fs_1.5.0
[88] data.table_1.14.0 magick_2.7.2 scattermore_0.7
[91] readbitmap_0.1.5 gmodels_2.18.1 lmtest_0.9-38
[94] RANN_2.6.1 whisker_0.4 fitdistrplus_1.1-3
[97] matrixStats_0.58.0 patchwork_1.1.1 shinyjs_2.0.0
[100] mime_0.10 evaluate_0.14 xtable_1.8-4
[103] jpeg_0.1-8.1 gridExtra_2.3 compiler_4.0.3
[106] tibble_3.1.6 KernSmooth_2.23-18 crayon_1.4.1
[109] htmltools_0.5.1.1 mgcv_1.8-34 later_1.1.0.1
[112] spdep_1.1-7 tiff_0.1-8 tidyr_1.2.0
[115] expm_0.999-6 DBI_1.1.1 MASS_7.3-53.1
[118] sf_0.9-8 boot_1.3-27 cli_3.1.1
[121] gdata_2.18.0 parallel_4.0.3 igraph_1.2.6
[124] pkgconfig_2.0.3 getPass_0.2-2 sp_1.4-5
[127] plotly_4.9.3 spatstat.sparse_2.0-0 foreach_1.5.1
[130] bslib_0.2.4 stringr_1.4.0 callr_3.7.0
[133] digest_0.6.27 sctransform_0.3.2 RcppAnnoy_0.0.18
[136] spatstat.data_2.1-0 rmarkdown_2.7 leiden_0.3.7
[139] uwot_0.1.10 gdtools_0.2.3 shiny_1.6.0
[142] gtools_3.8.2 lifecycle_1.0.1 nlme_3.1-152
[145] jsonlite_1.7.2 viridisLite_0.4.0 fansi_0.4.2
[148] pillar_1.7.0 lattice_0.20-41 fastmap_1.1.0
[151] httr_1.4.2 survival_3.2-10 glue_1.4.2
[154] png_0.1-7 iterators_1.0.13 class_7.3-18
[157] stringi_1.5.3 sass_0.3.1 irlba_2.3.3
[160] e1071_1.7-6 future.apply_1.7.0